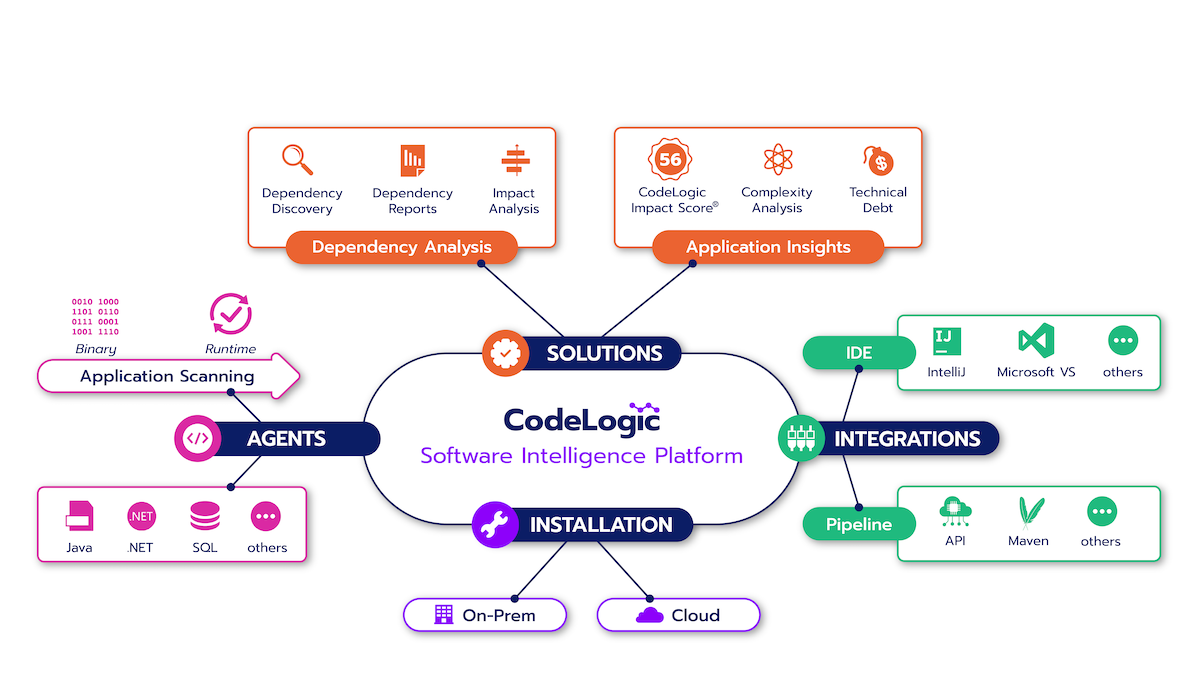
Overview of Our Continuous Software Intelligence Platform
The CodeLogic software intelligence platform provides application teams with an accurate understanding of their software structure in real-time, so they can make changes fearlessly. To deliver in-depth application data quickly, CodeLogic works in three basic phases:
CodeLogic agents scan your application, including databases.
A CodeLogic serverrunning in your environment stores and processes the data.
The data can be digested and shared through a variety of visualizations, reports, and interfaces, including IDE integrations.
The diagram above visualizes how the Codelogic software intelligence platform scans and delivers solutions and integrations.
Code Dependency Scanning
CodeLogic software intelligence profiles your application to gather data. Agents are installed in your test environments and/or build machines. For many agents, there are two approaches to scanning:
Binary: Static scans of compiled binaries capture structure, method calls, and some cross-service code dependencies.
Runtime: Profiling an application while it runs under tests, reveals additional code dependency relationships – especially between services or tiers.
Other agents use remote approaches to scan. For example, the SQL agent does not need to be installed on the database server. Instead, it connects to the database remotely, using a JDBC connection, in order to scan the schema and stored procedures.
The CodeLogic server gathers software intelligence from the IDE/coding environment, build environment, built artifacts, and SQL databases to detect relationships and complexities in your code.
Data storage and processing
CodeLogic is installed in your own environment, whether that is on-premises or in the cloud. Behind the scenes, it runs in containers with several services cooperating. We utilize a graph database to track code dependency relationships and optimize performance.
CodeLogic works against application meta-data only. For example, it can show that a method in a class references a column in a database. It may also know the number of instructions in that method and the column type. However, it does not record a copy of the method itself, nor the contents of the column. Your code and database data are never inside the CodeLogic server.
When CodeLogic scans of your application are complete, they are processed to match outbound references with the entities that are likely referenced. Sometimes, a reference will have no known matches. For example, we may see a database call referencing a table that has not yet been scanned. In this situation, CodeLogic keeps a record of the item or items it is searching for (the unscanned table). If that item is scanned in the future, the match will be made then. Data from multiple scans are brought together into a workspace.
Software Intelligence Summary
CodeLogic software intelligence helps development teams of every size better understand their applications from a macro-view to the data-level. CodeLogic’s different visualizations and interfaces enable various parts of an organization to derive useful information about how their systems work, so they can make accurate and informed decisions across the entire enterprise.